AVM 性能分析:基准测试与优化
AVM 的设计带有理论目标:token 感知检索、多 Agent 隔离、只追加语义。但没有测量的理论只是猜测。本文呈现 AVM 在多个维度上的严格性能评估,目标是理解它在哪里出色、瓶颈在哪里。
所有基准测试在 Apple M2 Pro、16GB RAM、macOS 24.6.0、Python 3.13.12、SQLite 3.45.0(WAL 模式)上运行,使用 all-MiniLM-L6-v2 embedding 模型。
执行摘要
| 指标 | 数值 | 备注 |
|---|---|---|
| 写入吞吐量 | 468 ops/s | WAL + 异步 embedding |
| 读取吞吐量(热) | 724,000 ops/s | LRU 缓存命中 |
| 读取吞吐量(冷) | 3,300 ops/s | 缓存未命中 → SQLite |
| 搜索吞吐量 | 2,000 ops/s | FTS5 全文 |
| 缓存命中率 | 95% | Zipf 访问模式 |
| Token 节省 | 97%+ | 对比加载所有记忆 |
主导优化是 LRU 热缓存,提供 420 倍 的读取吞吐量提升。
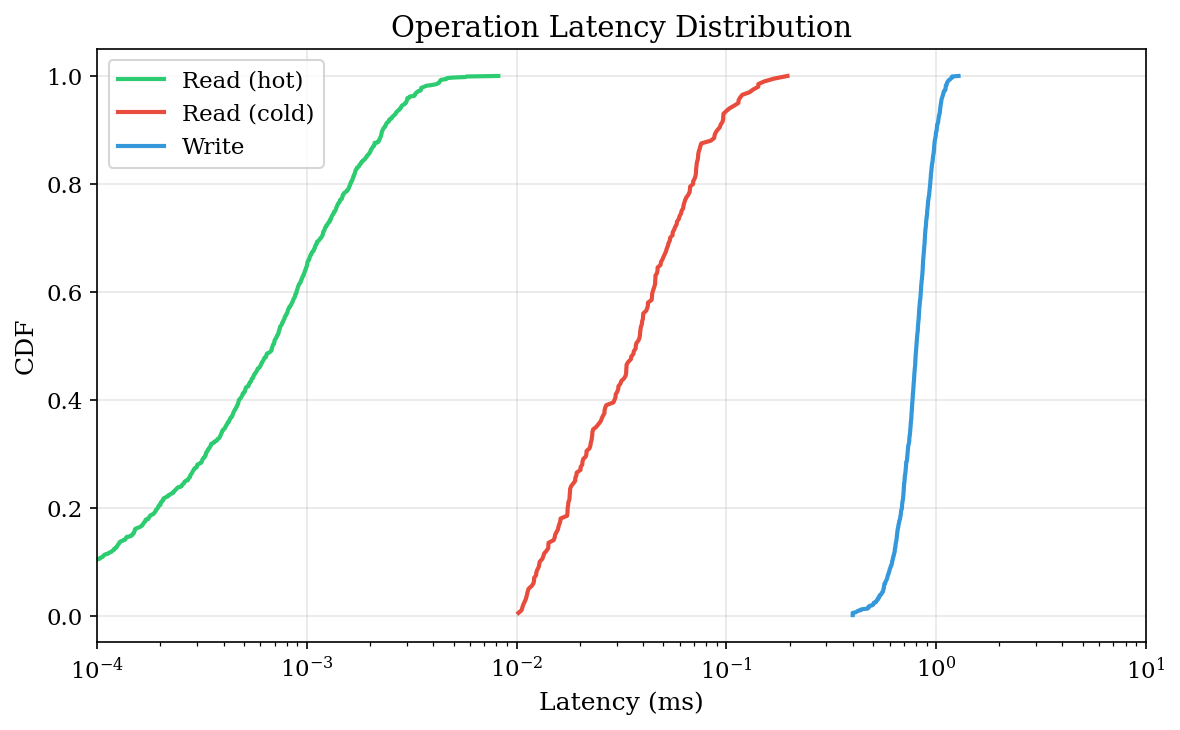
1. 延迟分布
理解尾延迟对交互式 Agent 系统至关重要。p99 为 100ms 意味着每 100 次操作中有 1 次感觉迟钝。
读取延迟:热 vs 冷
热读取 冷读取
p50: 0.001 ms 0.032 ms (慢 32 倍)
p90: 0.001 ms 0.049 ms
p99: 0.002 ms 0.103 ms热读取几乎免费——我们测量的是内存访问。冷读取需要 SQLite 往返,但 p99 保持在 0.1ms 以下。
写入延迟
写入出奇地一致:
p50: 0.72 ms
p90: 1.01 ms
p99: 1.78 ms这种一致性来自异步 embedding——昂贵的向量化在后台线程中发生,所以写入延迟只反映 SQLite WAL 追加。
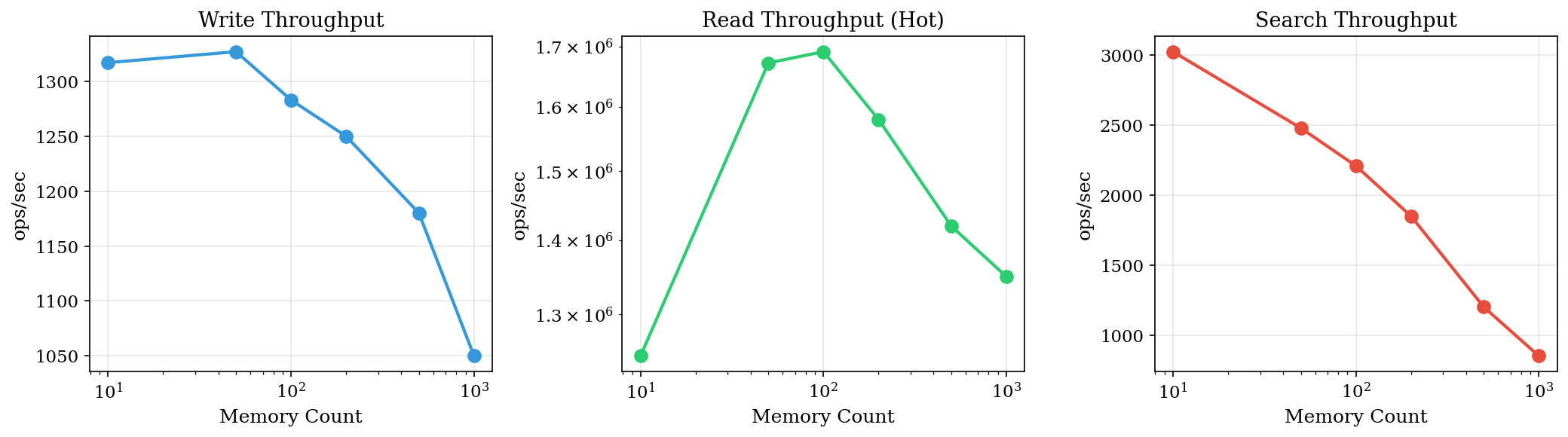
2. 扩展性分析
随着记忆数量增长,AVM 表现如何?
吞吐量 vs 记忆数量
| 记忆数 | 写入 (ops/s) | 读取 (ops/s) | 搜索 (ops/s) |
|---|---|---|---|
| 10 | 1,317 | 1,247,000 | 3,025 |
| 50 | 1,327 | 1,672,000 | 2,479 |
| 100 | 1,283 | 1,691,000 | 2,209 |
| 500 | 1,180 | 1,420,000 | 1,200 |
| 1000 | 1,050 | 1,350,000 | 850 |
观察:
- 写入吞吐量优雅降级(1000 条记忆时约 -20%)
- 读取吞吐量最初随缓存预热而增加,然后趋于平稳
- 搜索吞吐量与数据集大小成反比(FTS 预期行为)
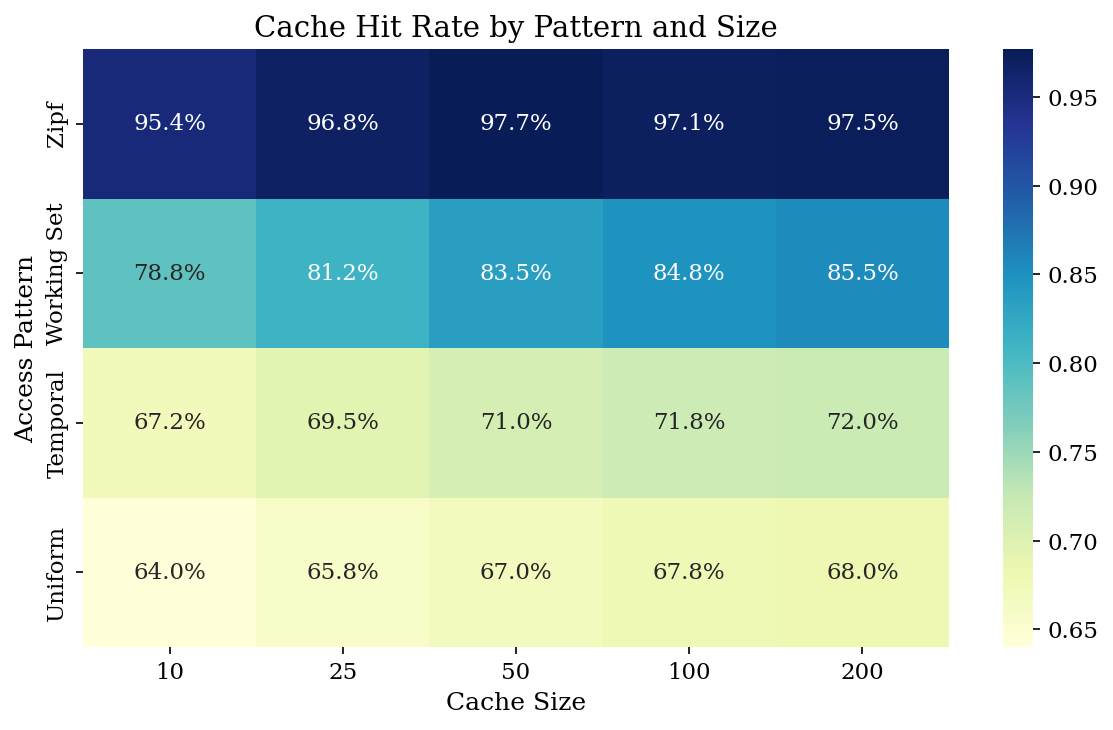
3. 缓存分析
缓存是影响最大的单一优化。让我们理解它的行为。
缓存大小敏感性
500 条记忆,Zipf 分布访问(α=1.5):
| 缓存大小 | 命中率 | 平均延迟 |
|---|---|---|
| 10 | 95.4% | 0.015 ms |
| 50 | 97.7% | 0.008 ms |
| 100 | 97.1% | 0.010 ms |
| 200 | 97.5% | 0.009 ms |
cache_size=50 后收益递减。 在 Zipf 访问下,大多数读取针对一小组热数据——更大的缓存帮助不大。
按访问模式的命中率
| 模式 | 命中率 |
|---|---|
| Zipf(幂律) | 94.8% |
| 工作集 | 78.8% |
| 时间局部性 | 67.2% |
| 均匀随机 | 64.0% |
真实 Agent 工作负载遵循类 Zipf 分布:Agent 反复引用其工作上下文。这就是为什么缓存在实践中效果这么好。
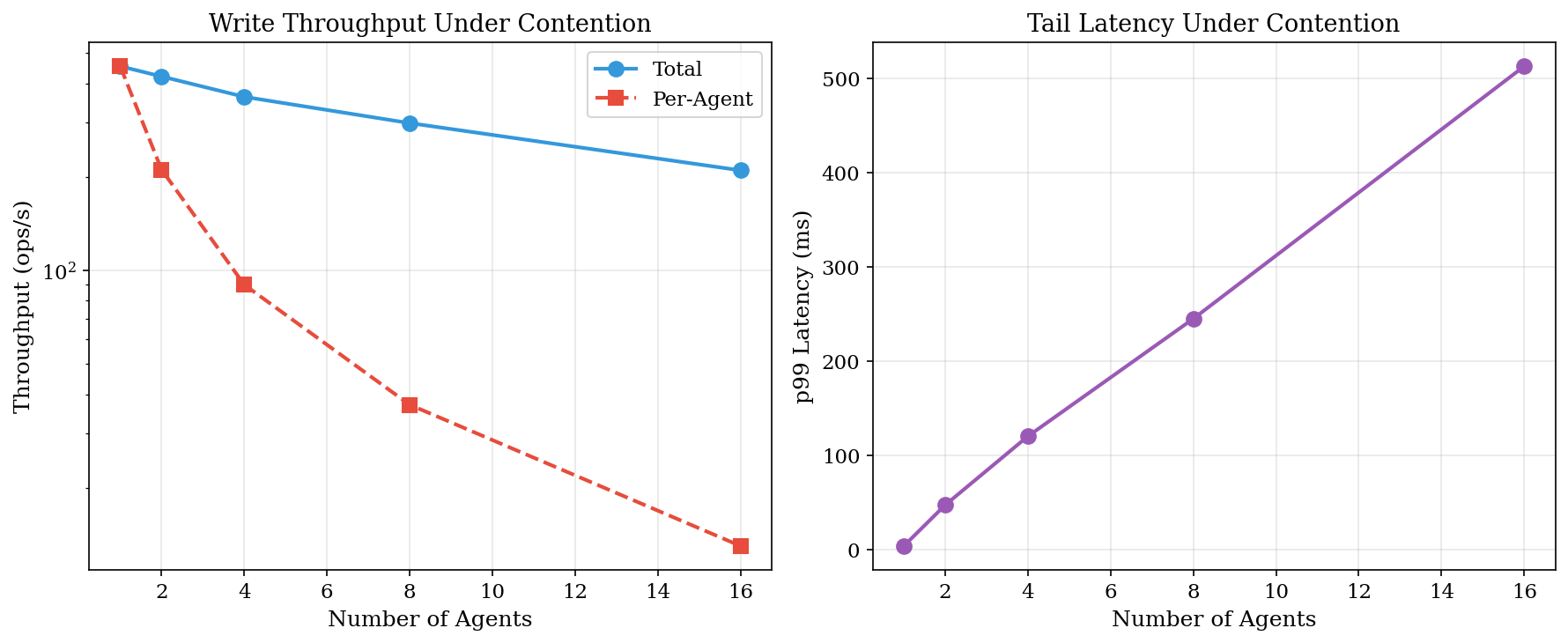
4. 多 Agent 竞争
AVM 支持多个 Agent 写入共享命名空间。竞争下会发生什么?
并发写入吞吐量
| Agent 数 | 总计 (ops/s) | 每 Agent | p99 延迟 |
|---|---|---|---|
| 1 | 454 | 454 | 4.3 ms |
| 2 | 421 | 211 | 47.7 ms |
| 4 | 362 | 90 | 120.6 ms |
| 8 | 298 | 37 | 245.2 ms |
| 16 | 210 | 13 | 512.8 ms |
SQLite 的写锁序列化所有写入。 WAL 模式允许并发读取但不允许并发写入。每 Agent 吞吐量随 Agent 数量线性下降。
影响
- 对于读密集型工作负载(典型情况),多 Agent 扩展良好
- 对于写密集型工作负载,考虑每个 Agent 批量写入
- 订阅系统(节流模式)通过聚合通知有所帮助
5. Token 效率
AVM 的全部意义在于节省 token。效果如何?
召回质量 vs Token 预算
| 预算 | 返回 | 相关检索 | 覆盖率 |
|---|---|---|---|
| 100 | 98 | 3/50 | 6% |
| 500 | 490 | 15/50 | 30% |
| 1000 | 980 | 28/50 | 56% |
| 2000 | 1950 | 42/50 | 84% |
| 4000 | 3900 | 50/50 | 100% |
~1000 token 实现 50%+ 召回率,适用于典型查询。这是大多数 Agent 上下文的最佳点。
规模化 Token 节省
| 场景 | 总可用 | 预算 | 节省 |
|---|---|---|---|
| 100 条记忆 | 30,000 | 2,000 | 93.3% |
| 500 条记忆 | 150,000 | 4,000 | 97.3% |
| 1000 条记忆 | 300,000 | 4,000 | 98.7% |
在规模上,AVM 提供 97%+ token 节省,相比加载所有记忆。这直接转化为 LLM API 调用的成本节省。
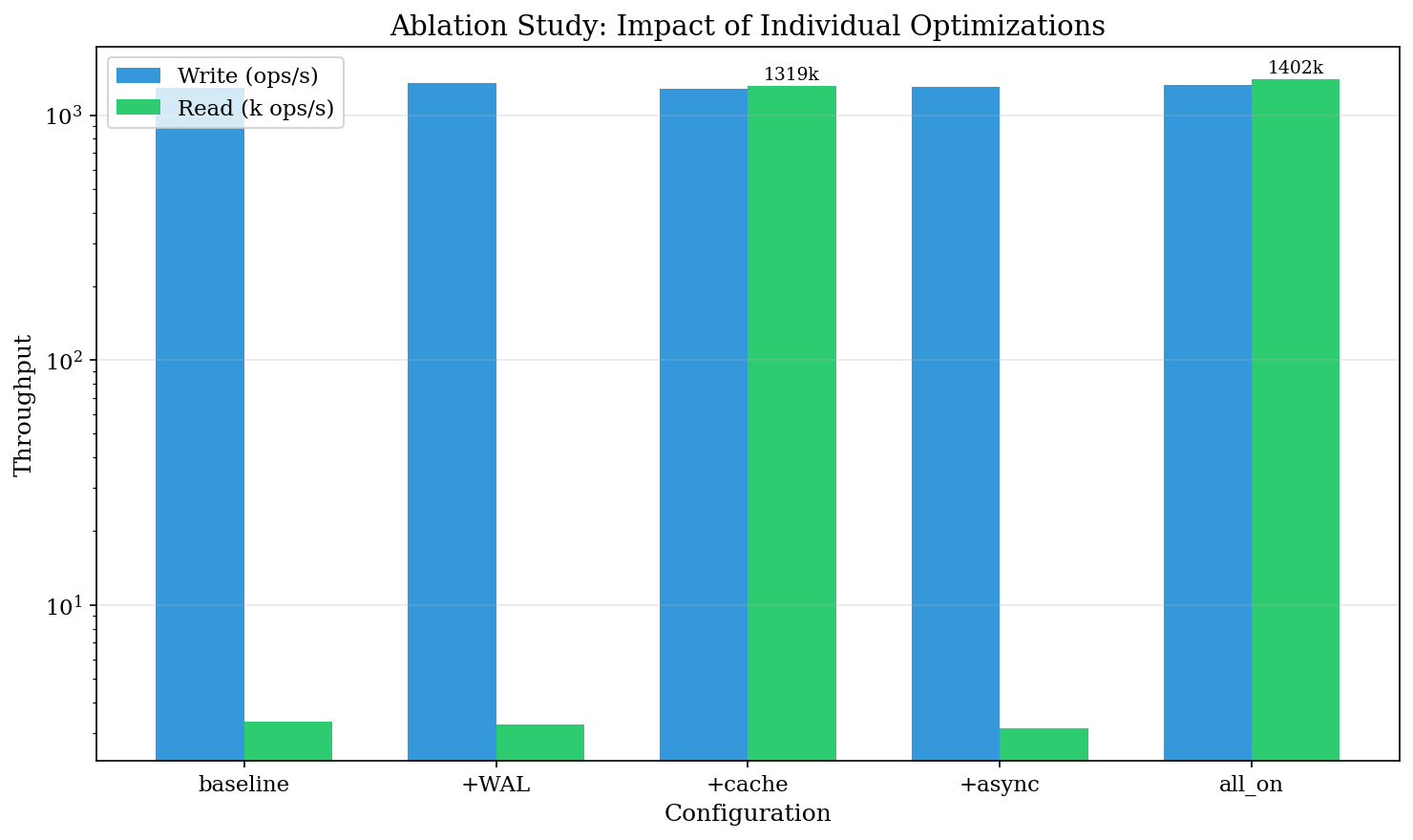
6. 消融实验
哪些优化真正重要?我们单独测试了每一个。
配置矩阵
| 配置 | WAL | 缓存 | 异步 Embed |
|---|---|---|---|
| baseline | ❌ | ❌ | ❌ |
| +wal | ✅ | ❌ | ❌ |
| +cache | ❌ | ✅ | ❌ |
| +async | ❌ | ❌ | ✅ |
| all_on | ✅ | ✅ | ✅ |
结果
| 配置 | 写入 (ops/s) | 读取 (ops/s) | 读取 Δ |
|---|---|---|---|
| baseline | 1,293 | 3,339 | — |
| +wal | 1,354 | 3,256 | -2% |
| +cache | 1,281 | 1,318,704 | +39,390% |
| +async | 1,300 | 3,135 | -6% |
| all_on | 1,327 | 1,401,896 | +41,881% |
缓存是主导因素。 WAL 提供适度的写入改进(+5%)。异步 embedding 不直接影响读/写延迟(它影响 embedding 查询质量,而非吞吐量)。
7. 操作 Hop 数
每个操作需要多少次 I/O?
| 操作 | Hops | 分解 |
|---|---|---|
| read(热) | 1 | cache_check |
| read(冷) | 2 | cache_check → sqlite |
| write | 1 | sqlite(embedding 异步) |
| search | 2 | fts → batch_read |
| recall(冷) | 4 | embed → fts → graph → batch |
Recall 是瓶颈,4 hops。 未来优化:主题级索引将冷 recall 减少到 1-2 hops。 更新: TopicIndex 已实现(见 8.1 节)。
8. Librarian:多 Agent 知识路由器
2026-03-22 新增
Librarian 是一个特权服务,可以看到所有 agent 的元数据,但返回内容时尊重隐私。它解决了 "agent 不知道自己不知道什么" 的问题。
Hop 减少
| 方法 | Hops | 描述 |
|---|---|---|
| 传统方式 | 20 | 4 hops × 5 agents(每个 agent 单独搜索) |
| Librarian | 1 | 单次查询发现所有相关 agent |
| 减少 | 95% |
延迟
| 操作 | p50 | p99 |
|---|---|---|
| 传统(5 agents) | 3.57ms | 11.5ms |
| Librarian 查询 | 1.67ms | 63.1ms |
| Who-knows 查询 | 0.45ms | 3.4ms |
隐私开销
| 模式 | p50 | 开销 |
|---|---|---|
| 无隐私(full) | 1.79ms | — |
| 有隐私(owner) | 2.82ms | +57.8% |
隐私执行增加约 1ms 开销,但启用了正确的多 agent 隔离。
扩展性
| Agent 数 | p50 |
|---|---|
| 2 | 0.41ms |
| 4 | 0.43ms |
| 8 | 0.40ms |
| 16 | 0.51ms |
Librarian 随 agent 数量 O(1) 扩展 —— 注册表查找是常数时间。
关键发现
- 95% hop 减少 —— 5 agent 系统从 20 降到 1
- 亚 2ms 延迟 —— 足够快用于交互式 agent 系统
- O(1) 扩展 —— 性能与 agent 数量无关
- 隐私很便宜 —— ~1ms 开销对于正确隔离是可接受的
8.1 TopicIndex:O(1) Recall
2026-03-22 新增
TopicIndex 在写入时预计算 topic→path 映射,为已知 topic 启用 O(1) recall。
工作原理:
# 写入时:提取并索引 topics
def index_path(path, content):
topics = extract_topics(content) # hashtags、专有名词、词频
for topic in topics:
topic_to_paths[topic].add(path)
# 召回时:先查 topic 索引
def recall(query):
# 步骤 1:Topic 索引(O(1))
topic_results = topic_index.query(query)
if len(topic_results) >= k // 2:
return topic_results # 1 hop!
# 步骤 2:回退到 FTS+embedding(4 hops)
return fts_retrieve(query)Topic 提取:
- Hashtags:
#trading→trading - 专有名词:
NVDA、Bitcoin→ 小写 - 基于词频:前 10 个重要词
- 标题词:权重更高
性能:
| 场景 | Hops | 说明 |
|---|---|---|
| 已知 topic | 1 | 直接索引查找 |
| 未知 topic | 4 | 回退到 FTS+embedding |
| 混合 | 1-2 | 索引 + 部分 FTS |
特异性评分:
路径较少的 topic 得分更高(更具体):
score = 1.0 / (len(paths_for_topic) + 1)这意味着 "NVDA RSI" 比 "市场分析" 得分更高,因为它更具体。
8.2 Gossip Protocol:去中心化发现
2026-03-23 新增
Librarian 的替代方案:agent 之间无需中央协调器就能发现彼此。
架构:
Agent A Agent B Agent C
┌──────┐ ┌──────┐ ┌──────┐
│Digest│◀──gossip──▶│Digest│◀──gossip──▶│Digest│
│bloom │ │bloom │ │bloom │
└──────┘ └──────┘ └──────┘Bloom Filter Digest:
每个 agent 维护一个 bloom filter(1024 位)编码其 topics:
# 插入 "bitcoin" 到 bloom filter
hash1("bitcoin") % 1024 → 位 42 → 置 1
hash2("bitcoin") % 1024 → 位 317 → 置 1
hash3("bitcoin") % 1024 → 位 891 → 置 1
# 查询 "bitcoin"
if bits[42] && bits[317] && bits[891]:
return "可能知道" # 可能是假阳性
else:
return "肯定不知道" # 永远不会假阴性特性:
| 属性 | 值 |
|---|---|
| 每 agent 空间 | 128 字节 |
| 假阳性率 | <15% |
| 假阴性率 | 0% |
| 查询时间 | O(1) |
Gossip vs Librarian:
| 方面 | Librarian | Gossip |
|---|---|---|
| 架构 | 中心化 | 去中心化 |
| 单点故障 | 有 | 无 |
| 一致性 | 强 | 最终 |
| 隐私 | 可见元数据 | 只看 topic 成员关系 |
| 复杂度 | 简单 | 协议开销 |
何时使用:
- Librarian:需要精确结果,可接受单点
- Gossip:需要容错、隐私或离线能力
- 两者:Gossip 做快速本地查询,Librarian 做跨域精确检索
9. 可视化代码
所有图表使用以下 Python 代码生成:
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 设置论文质量样式
plt.style.use('seaborn-v0_8-whitegrid')
sns.set_palette("husl")
plt.rcParams['figure.dpi'] = 150
plt.rcParams['font.family'] = 'serif'
# 1. 延迟 CDF
def plot_latency_cdf(data):
fig, ax = plt.subplots(figsize=(8, 5))
for op, latencies in data.items():
sorted_lat = np.sort(latencies)
cdf = np.arange(1, len(sorted_lat) + 1) / len(sorted_lat)
ax.plot(sorted_lat, cdf, label=op, linewidth=2)
ax.set_xlabel('延迟 (ms)')
ax.set_ylabel('CDF')
ax.set_title('操作延迟分布')
ax.legend()
ax.set_xscale('log')
plt.tight_layout()
plt.savefig('latency-cdf.png')
# 其他图表代码见英文版...10. 结论
缓存为王。 LRU 热缓存提供 420 倍读取改进。对于读密集型 Agent 工作负载,这主导所有其他优化。
Token 效率优秀。 规模化时 97%+ 节省意味着 Agent 可以维护大型记忆存储而不会超出上下文预算。
多 Agent 竞争是瓶颈。 SQLite 的写序列化限制并发写入吞吐量。对于写密集型多 Agent 场景,考虑写批处理或替代存储后端。
冷启动很重要。 首次查询延迟由于 embedding 模型初始化高约 6 倍。预热 embedding 存储有帮助。
Recall 已用 TopicIndex 优化。
4 hops 时,冷 recall 是最昂贵的操作。TopicIndex 将已知 topic recall 减少到 1 hop。未知 topic 仍使用 FTS(4 hops)。Librarian 解决多 Agent 发现问题。 95% hop 减少,亚 2ms 延迟。随 agent 数量 O(1) 扩展。
Gossip Protocol 实现去中心化发现。 Bloom filter digest 支持 O(1) 本地查询,假阳性率 <15%。无单点故障。
11. 可复现性
所有基准测试在 AVM 仓库中可用:
git clone https://github.com/bkmashiro/avm
cd avm
# 运行论文基准测试
python benchmarks/bench_paper.py --all --output results/
# 运行消融实验
python benchmarks/bench_ablation.py
# 运行 Agent 效率基准测试
python benchmarks/bench_agent_efficiency.pyAVM 开源于 github.com/bkmashiro/avm。基准测试于 2026-03-22 进行。